Desde que o Google-Extended entrou no radar do mercado, muita gente passou a tratá-lo como um botão geral de “não use meu conteúdo em IA”.
O problema é que essa leitura mistura camadas diferentes: crawling, indexação, exibição de trechos na Busca, treinamento de modelos e uso do conteúdo em experiências de IA. Quando tudo isso vira a mesma coisa, a decisão técnica fica pior do que a dúvida inicial.
A documentação oficial do Google separa essas peças com bastante clareza.
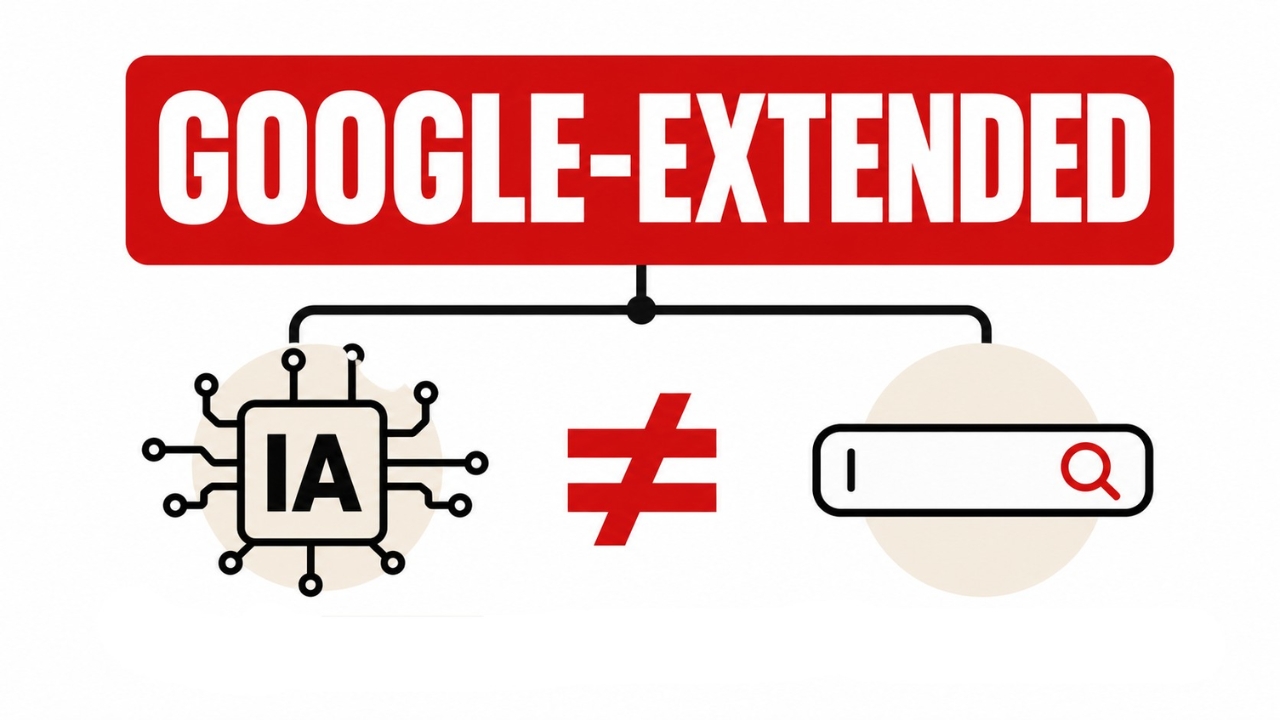
O Google-Extended é um token de controle no robots.txt para gerenciar se o conteúdo rastreado pelo Google pode ser usado em certos sistemas de IA do próprio Google. Ele não altera a inclusão do site no Google Search e não é usado como sinal de ranking.
Para recursos de IA dentro da Busca, como AI Overviews e AI Mode, o Google orienta olhar para os controles tradicionais de Search, como nosnippet, data-nosnippet, max-snippet e noindex.
O que é Google-Extended?
O Google-Extended é um token de robots.txt criado para que publishers e proprietários de sites decidam se o conteúdo rastreado pelo Google pode ser usado no treinamento de futuras gerações dos modelos Gemini e em mecanismos de grounding ligados ao ecossistema Gemini e Vertex AI.
Em linguagem menos burocrática: ele é um controle de governança de conteúdo para IA, não uma alavanca de performance orgânica.
Esse ponto importa porque o mercado costuma reduzir o assunto a uma falsa escolha entre “liberar tudo” ou “sumir da busca”. Não é isso que a documentação diz.
O próprio Google afirma que o Google-Extended não afeta a inclusão de um site no Google Search e não funciona como fator de ranking.
Há outra nuance importante: o Google-Extended não tem um user-agent HTTP próprio aparecendo separadamente nos logs.
O rastreamento acontece com user agents já existentes do Google; o token Google-Extended funciona como mecanismo de controle dentro do robots.txt.
Isso significa que muita gente procura “o robô Google-Extended” nos logs do servidor e conclui, erradamente, que a diretiva “não está funcionando”.
Google-Extended afeta SEO?
Não diretamente. Se a pergunta for “bloquear Google-Extended derruba ranking?”, a resposta oficial é não. O Google diz que esse token não interfere na inclusão do site na Busca e não é usado como sinal de ranking.
A confusão aparece porque SEO técnico trabalha com vários controles parecidos na superfície e muito diferentes na função. robots.txt lida com acesso de crawler. noindex lida com indexação. nosnippet e max-snippet lidam com o quanto do conteúdo pode aparecer ao usuário.
Quando alguém aplica uma diretiva pensando em uma camada e, na prática, mexe em outra, o diagnóstico fica torto.
Por isso a pergunta madura não é “isso ajuda ou atrapalha SEO?”. A pergunta madura é: qual comportamento você quer controlar, exatamente?
Se a meta é limitar treinamento e certos usos em sistemas de IA do Google, o Google-Extended entra na conversa. Se a meta é controlar presença na Busca, snippet ou indexação, você está falando de outros instrumentos.
Google-Extended bloqueia AI Overviews e AI Mode?
Esse é o ponto em que mais gente se perde.
Para AI Overviews e AI Mode, o Google diz que os controles relevantes são os da própria Busca.
A documentação afirma que a IA está integrada ao Search e, por isso, o controle de rastreamento para Search passa por Googlebot; para limitar o que pode ser mostrado a partir das suas páginas em recursos de IA da Busca, o Google recomenda nosnippet, data-nosnippet, max-snippet ou noindex.
Na mesma página, a empresa separa esse tema do Google-Extended, indicando-o para limitar treinamento e grounding em outros sistemas do Google.
A implicação prática é simples: bloquear Google-Extended não é a mesma coisa que bloquear a aparição do seu conteúdo em experiências de IA dentro da Busca.
Se a preocupação é AI Overviews ou AI Mode, o raciocínio precisa sair da obsessão com um token e voltar para preview controls, indexação e elegibilidade na Search.
O próprio Google diz que, para uma página aparecer como link de apoio nesses recursos, ela precisa estar indexada e elegível para aparecer no Google Search com snippet.
É justamente aqui que o debate descamba. Muita gente usa “IA do Google” como um bloco único. Só que o próprio Google não documenta assim. E quando a plataforma separa, o editor também deveria separar.
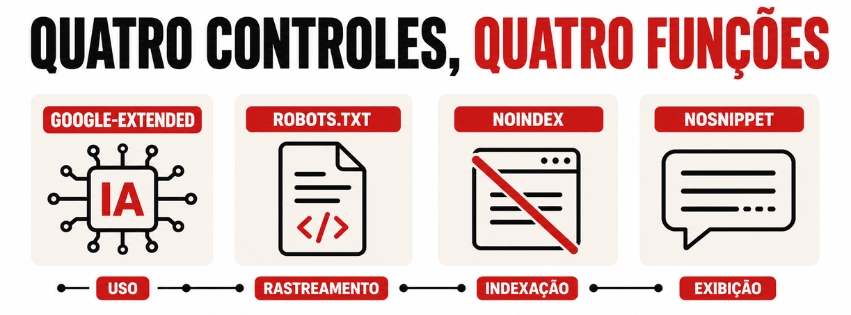
Google-Extended x robots.txt, noindex e nosnippet
Esses termos vivem misturados em conversas apressadas, mas controlam coisas diferentes.
- robots.txt serve principalmente para gerenciar o acesso de crawlers a URLs do site. O Google lembra que ele não foi feito como mecanismo para tirar uma página da Busca.
- Uma URL bloqueada em robots.txt ainda pode aparecer nos resultados se houver links apontando para ela, mesmo sem descrição.
- noindex é outro assunto. Ele é usado para impedir que a página apareça indexada nos resultados de busca.
- Já nosnippet, data-nosnippet e max-snippet controlam a exibição de trechos e partes do conteúdo ao usuário em superfícies da Busca.
A documentação do Google também deixa claro que, no contexto dos recursos de IA do Search, são esses controles de preview que devem ser usados para limitar a informação mostrada a partir da página.
Existe ainda um detalhe técnico que ajuda a limpar a confusão: nas meta tags de robots suportadas pelo Google, os tokens específicos reconhecidos para nome do crawler são googlebot e googlebot-news.
Em outras palavras, não existe uma “meta tag Google-Extended” equivalente para você colocar no <head> e resolver tudo por página. Google-Extended é documentado como token de robots.txt, não como meta tag.
Se você gosta de uma fórmula curta, ela é esta: Google-Extended trata de uso do conteúdo em certos sistemas de IA do Google; noindex trata de presença na Busca; nosnippet e companhia tratam de exibição; robots.txt trata de acesso de crawler.
Misturar essas camadas produz decisões ruins com aparência de decisão técnica.
Como bloquear uso por IA com Google-Extended no robots.txt
Na prática, o controle é feito no arquivo robots.txt.
Se a decisão for bloquear todo o site para Google-Extended, a lógica é esta:
[User-agent: Google-Extended
Disallow: /]
Se a decisão for bloquear apenas uma área específica do site, como um diretório de conteúdos premium, a lógica pode seguir este modelo:
[User-agent: Google-Extended
Disallow: /conteudos-premium/
Allow: /]
A própria documentação mostra que o token pode ser usado como outros grupos de robots.txt, com regras de Allow e Disallow por caminho. Isso permite um controle mais cirúrgico do que a conversa pública costuma sugerir.
Também vale lembrar que a implementação depende da lógica do robots.txt, não de uma interface mágica do Search Console.
E, como Google-Extended não possui um user-agent HTTP separado, a validação operacional exige mais critério.
Em vez de esperar ver “Google-Extended” passando no log como robô independente, o correto é entender que se trata de um token de controle aplicado ao conteúdo rastreado pelo Google.
Quando faz sentido usar Google-Extended

O Google-Extended faz sentido quando a preocupação central é política de uso do conteúdo em IA, não performance de busca.
Um publisher com acervo original, uma empresa com documentação proprietária, um portal com colunistas especializados ou uma marca que investe pesado em pesquisa própria pode querer limitar esse uso por razões editoriais, jurídicas, estratégicas ou comerciais.
Nesses casos, o debate não é “como ganhar clique agora”, mas “como o conteúdo da operação pode ser reutilizado em ambientes de IA do Google”.
Ele também faz sentido quando a empresa quer separar frentes. Um site pode continuar visível na Busca e, ao mesmo tempo, restringir esse uso específico em sistemas de IA do Google.
Essa possibilidade existe justamente porque Google-Extended, segundo a documentação oficial, não funciona como sinal de ranking nem tira o site do Search por si só.
O que ele não resolve é uma estratégia ampla de proteção contra todo e qualquer uso por IA na web. Primeiro, porque a própria documentação de robots.txt lembra que esse tipo de instrução depende de o crawler obedecer às regras.
Segundo, porque Google-Extended é um token do ecossistema Google, não um padrão universal que governa todos os sistemas de terceiros.
Leia também:
Conclusão
O Google-Extended é útil justamente quando deixa de ser tratado como símbolo e volta a ser tratado como instrumento.
Ele não é um “botão anti-IA” universal. Não é um hack de SEO. Não é atalho para sair da Busca nem mecanismo para controlar snippets.
É um recurso específico para controlar se o conteúdo rastreado pelo Google pode alimentar certos sistemas de IA do próprio Google.
Quando essa distinção fica clara, a arquitetura da decisão também melhora: Search é uma camada, preview é outra, indexação é outra, treinamento e grounding são outra.
Em temas assim, precisão conceitual já é uma vantagem competitiva. Porque, em tecnologia de busca, quase sempre o dano começa quando nomes parecidos passam a ser tratados como se fossem a mesma coisa.